
This post is the first in a series where we want to analyse the behaviour of STATA in terms of cross-version reproducibility of results. In the current post, we will see inconsistent results for built-in STATA commands across versions, in a future post I plan to illlustrate problematic interactions with user-contributed code in the form of so-called .ado files (I will refer to those as packages). We will draw on real-world examples in the form of replication packages published together with academic papers in the Economic Journal. We will perform computational experiments by running identical code and data with different versions of STATA.
The starting point of this exploration is a blog post by the president of StataCorp from 2019 (with a similar message on the STATA website):
Although I am biased of course, I believe Stata has the best backward compatibility record of any statistical software. Stata is the only statistical software package, commercial or open source, that I am aware of that has a strong built-in version control system to allow scripts and programs written years ago to continue to work in modern versions of the software.
We will encounter below one example where we found behaviour which is incompatible with this statement. The aim of this post is not to discredit STATA in any way, but to provide hopefully useful advice on how to avoid distributing unreproducible code. In general, there is nothing which would make STATA better or worse suited to achieve reproducibility, and in this sense I humbly disagree with the above statement. Each language presents its own set of challenges, and being aware of those goes a long way. We reserve a comparison of computing languages in terms of being helpful to writing reproducible code for another occasion.
Stata version x Command
STATA has a command version x which, if called, will mimick the STATA interpreter version x. The entry for help version gives a list of all known changes in behaviour if one sets version x, relative to the current version. The fact that this works is on the one hand nothing but remarkable - the code base of STATA must have changed considerably over the last few decades, surely countless bugs must have been fixed, etc, therefore ensuring that this works must require tremendous effort; on the other hand, it is obvious that version x does not replace the currently running STATA binary with the one of previous STATA version x, so any interactions of that binary with the current computing environment (OS, support libraries etc) could lead to unexpected behaviour. Indeed, we will document such behaviour below.
In general, Data Editors would not require that your code needs to be reproducible with all versions of STATA; quite on the contrary, we want a very specific description of the required environment. Another aim of this post is thus to clarify some (unexpected) effects of the version command, and to counter the belief that setting version will guarantee cross version reproducibility.
Case Study: xporegress in Burchardi et al (EJ 2024)
- We found different results for
xporegressacross STATA versions 16 and v 18 while checking the Burchardi et al (EJ 2024) paper.xporegressis a built-in STATA command. - Notice we don’t know whether there is anything wrong in
xporegressper se, or whether some other aspect of STATA code changed in a way which leads to different results across both verions. We are also agnostic about whether the authors were writing code in any way incompatible with STATA version 18, because: - To us, this is irrelevant, as we want to be able to rely on the promise embedded in
version 16solving all issues. The authors setversion 16, as well as all required random seeds, in the correct fashion.
The Burchardi et al package features high quality of code and exceptional collaboration on behalf of the authors. All results replicate exactly on STATA version 16, as indicated in their package readme. They were the first to point out the issue with xporegress to me. Thanks to them! 🤝
Step 1: Safe Environment via docker
- We want to minimize the risk that anything in our findings is driven by my local STATA installation, and its interaction with my OS. A good solution to this is a containerized environment, for example via
docker. - We want to have 2 docker containers with version 16 and 18 respectively. We basically want to test the effect of the
version 16command on the stata 18 binary. - The dedicated repository of docker images provided by the AEA Data Editor Lars Vilhuber is going to be very helpful here. The prebuilt docker images for different stata versions are available here on dockerhub.
- We can run STATA 16 and STATA 18 as if we had two separate machines inside an isolated environment (a container) on our own computer.
- Notice that there are no user contributed packages installed into those containers. Furthermore, Burchardi et al provide
.adofiles for add-on packages with their code. So, we have a clean slate.
Step 2: Code to Run Experiment
To minimize further mistakes from manually handling code and results, I wrote some julia code which is available here. It downloads the Burchardi et al package from zenodo.org, unpacks it, modifies it slightly (so that it only produces the required appendix table B8 where the discrepancy arises), and then launches the respective STATA containers with the identical code and data; first version 16, where results correspond exactly to the paper, and then version 18, where they do not. The point being, given the promise contained in the version 16 command, results should correspond across versions.
If you follow instructions contained therein, you will see the following output in your terminal:
floswald@PTL11077 ~/g/E/b/stataversion (main)> julia --project=. runblog.jl
[ Info: downloading record Burchardi
[ Info: content of /Users/floswald/git/EJData/blogs/stataversion/Burchardi/3-replication-package
[".DS_Store", "Code", "Data", "Materials", "Output", "README.pdf"]
[ Info: done downloading
[ Info: run with stata 16
[ Info: STATA version 16, docker IMG tag 2023-06-13
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
[ Info: renaming /Users/floswald/git/EJData/blogs/stataversion/Burchardi/3-replication-package/Output/Tables/DEMED_AppendixTableB8_dummy.tex
[ Info: renaming /Users/floswald/git/EJData/blogs/stataversion/Burchardi/3-replication-package/Output/Tables/DEMED_AppendixTableB8_index.tex
["/Users/floswald/git/EJData/blogs/stataversion/Burchardi/3-replication-package/Output/Tables/DEMED_AppendixTableB8_dummy-v16.tex", "/Users/floswald/git/EJData/blogs/stataversion/Burchardi/3-replication-package/Output/Tables/DEMED_AppendixTableB8_index-v16.tex"]
[ Info: run with stata 18
[ Info: STATA version 18, docker IMG tag 2024-04-30
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
[ Info: done 👋Step 3: Results
The code repository also contains a short latex script which will compile the tables outputted from each docker container into a simple table. We can compare the result for each table across both versions. We can see for 2 columns a noticeable difference, both in estimates as well as in standard errors. The numbers in equally colored shapes should be identical.
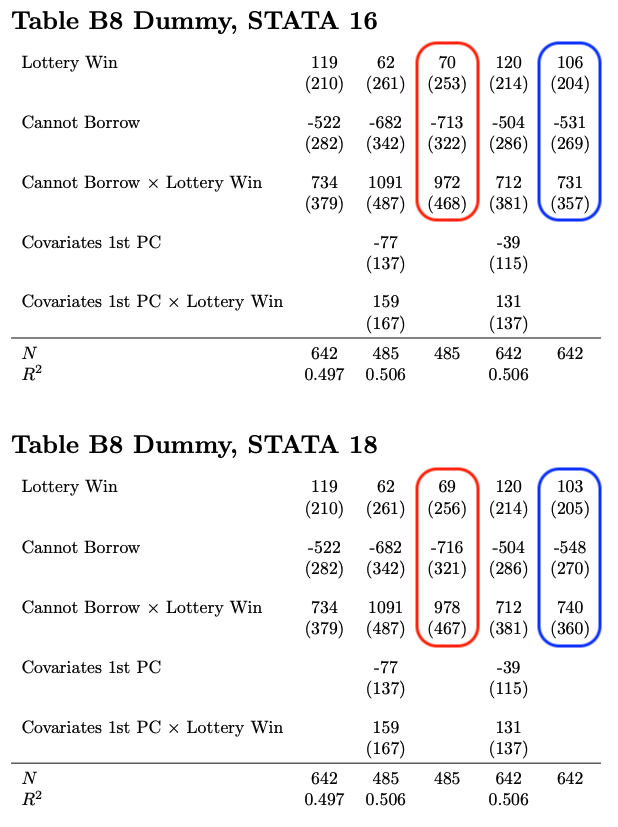
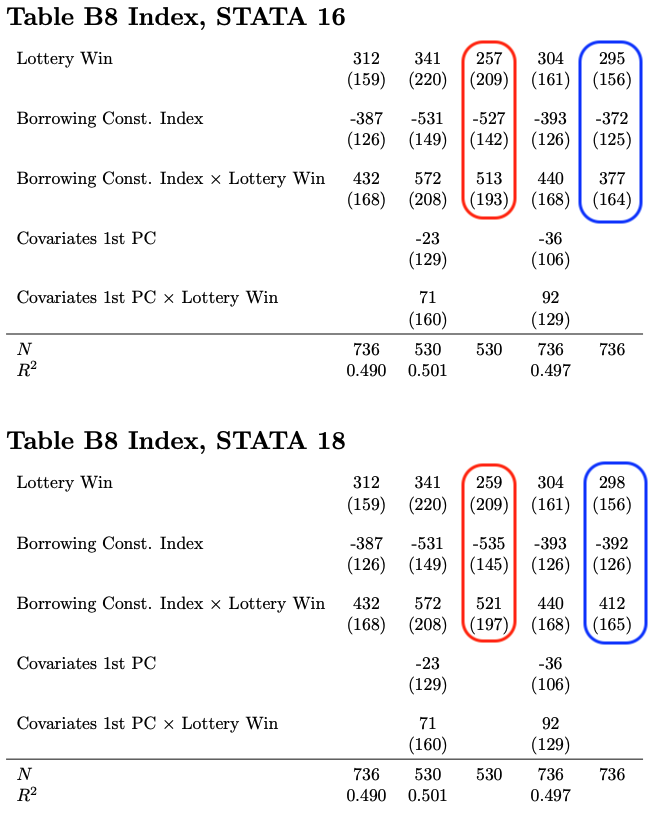
Conclusion
The authors of Borrowing Constraints and Demand for Remedial Education: Evidence from Tanzania (forthcoming EJ 2024) have provided an excellent replication package which is available here. They alerted our team to a discrepancy arising from the xporegress command across STATA versions 16 vs 18. This is despite their correct usage of the version 16 command, and despite the insistence on the fact that everything will just work in the initial quote.